Digital Newsletter
Each week our editor Phil Alsop rounds up the most popular articles, videos and expert opinions. We compile this into a Digital Newsletter and send it straight to your inbox every week.
Digital Magazines
We'll let you know each time a new edition of Digitalisation World is released so that you're always kept up-to-date with the latest and greatest news and press releases.
Video Magazines
The Digitalisation World Video magazine contains the latest Zoom interviews with experts in the industry.
High-dimensional data, which includes communications networks access data, types of medical data, and images remain difficult to process due to its complexity, making it a challenge to obtain the characteristics of the target data. Until now, this made it necessary to use techniques to reduce the dimensions of the input data using deep learning, at times causing the AI to make incorrect judgments.
Fujitsu has combined deep learning technology with its expertise in image compression technology, cultivated over many years, to develop an AI technology that makes it possible to optimize the processing of high-dimensional data with deep learning technology, and to accurately extract data features. It combines information theory used in image compression with deep learning, optimizing the number of dimensions to be reduced in high-dimensional data and the distribution of the data after the dimension reduction by deep learning.
Akira Nakagawa, (Associate fellow) of Fujitsu Laboratories commented, "This represents an important step to addressing one of the key challenges in the AI field in recent years: capturing the probability and distribution of data. We believe that this technology will contribute to performance improvements for AI, and we're excited about the possibility of applying this knowledge to improve a variety of AI technologies."
Development Background
In recent years, there has been a surge in demand for AI-driven big data analysis in various business fields. AI is also expected to help support the detection of anomalies in data to reveal things like unauthorized attempts to access networks or abnormalities in medical data for thyroid values or arrhythmia data.
Challenges
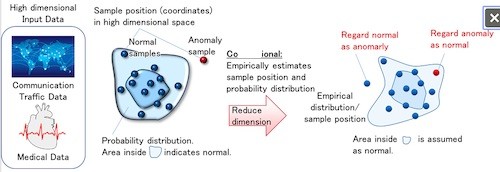
Data used in many business operations is high-dimensional data. As the number of dimensions of data increases, the complexity of calculations required to accurately characterize the data increases exponentially, a phenomenon is widely known as the "Curse of Dimensionality"(1). In recent years, a method of reducing the dimensions of input data using deep learning has been identified as a promising candidate for helping to avoid this problem. However, since the number of dimensions is reduced without considering the data distribution and probability of occurrence after the reduction, the characteristics of the data have not been accurately captured, and the recognition accuracy of the AI is limited and misjudgment can occur. Solving these problems and accurately acquiring the distribution and probability of high-dimensional data remain important issues in the AI field.
About the Newly Developed Technology
Fujitsu has developed the world's first AI technology that accurately captures the characteristics of high-dimensional data without labeled training data.
Fujitsu tested the new technology against benchmarks for detecting data abnormalities in different fields, including communication access data distributed by the International Society for Data Mining "Knowledge Discovery and Data Mining (KDD)", thyroid gland numerical data and arrhythmia data distributed by the University of California, Irvine. The newly developed technology successfully achieved the world's highest accuracy in all data with up to a 37% improvement over conventional deep-learning-based error rates. Since this technology solves one of the fundamental challenges in the field of AI, which is how to accurately capture the characteristics of data, it is expected to prove an important development to unlocking a wide range of new applications.
The technical features of the developed technology are as follows.
1. Proof of theory that accurately captures the characteristics of data
In compression of image and audio data, which are both high-dimensional data consisting of several thousand to several million dimensions, the distribution and occurrence probability of the data have been clarified through many years of research, and methods for reducing the number of dimensions by means of discrete cosine transform(2) and other methods optimized for these known distributions and probabilities have already been established. It has been theoretically proven that the amount of compressed data information can be minimized when the degradation between the original image/sound and the restored image/sound is suppressed to a constant level by restoring data using the distribution of data after dimension reduction and the probability of occurrence. Inspired by image compression theory, Fujitsu has proved a new mathematical theory for the first time in the world that, for high-dimensional data with unknown distribution and probability, such as communication network access data and medical data, the dimensionality of the data is reduced by an auto-encoder(3), which is a neural network, and when the data is restored, the degradation between the original high-dimensional data and the restored data is kept to a constant value while the amount of information after the dimensionality reduction is minimized, enabling the characteristics of the original high-dimensional data to be accurately captured and the dimensionality to be reduced to a minimum.
2. Dimension reduction technology using deep learning
In general, deep learning can determine the combination of parameters that minimize the objective cost even in complex problems by defining the objective cost that need to be minimized. Using this feature, Fujitsu introduced parameters to control both the auto-encoder which reduces the dimension of data and the distribution of data after dimensionality reduction. Our method calculates the amount of information after compression as an objective cost and optimized it through deep learning. This allows the dimensionally reduced distribution and the probability of the data to be accurately characterized when optimized according to the mathematical theory described in 1 above.
Going forward, Fujitsu will promote the practical application of the newly-developed technology, with the aim of putting it into practical use by the end of fiscal 2021, and will apply it to even more AI technologies.
(1) Curse of Dimensionality phenomenon describing exponential increase in computational complexity as the number of dimensions of data increases.
(2) Discrete cosine transform a type of Fourier transform that transforms an image or audio signal into the intensity of a frequency component.
(3) Autoencoder a neural network-based unsupervised dimensional compression technique.